|
在搭建高吞吐量web应用这个议题上,NginX和Node.js可谓是天生一对。他们都是基于事件驱动模型而设计,可以轻易突破Apache等传统web服务器的C10K瓶颈。预设的配置已经可以获得很高的并发,不过,要是大家想在廉价硬件上做到每秒数千以上的请求,还是有一些工作要做的。
这篇文章假定读者们使用NginX的HttpProxyModule来为上游的node.js服务器充当反向代理。我们将介绍Ubuntu 10.04以上系统sysctl的调优,以及node.js应用与NginX的调优。当然,如果大家用的是Debian系统,也能达到同样的目标,只不过调优的方法有所不同而已。
网络调优
如果不先对Nginx和Node.js的底层传输机制有所了解,并进行针对性优化,可能对两者再细致的调优也会徒劳无功。一般情况下,Nginx通过TCP socket来连接客户端与上游应用。
我们的系统对TCP有许多门限值与限制,通过内核参数来设定。这些参数的默认值往往是为一般的用途而定的,并不能满足web服务器所需的高流量、短生命的要求。
这里列出了调优TCP可供候选的一些参数。为使它们生效,可以将它们放在/etc/sysctl.conf文件里,或者放入一个新配置文件,比如/etc/sysctl.d/99-tuning.conf,然后运行sysctl -p,让内核装载它们。我们是用sysctl-cookbook来干这个体力活。
需要注意的是,这里列出来的值是可以安全使用的,但还是建议大家研究一下每个参数的含义,以便根据自己的负荷、硬件和使用情况选择一个更加合适的值。
重点说明其中几个重要的。
net.ipv4.ip_local_port_range
为了替上游的应用服务下游的客户端,NginX必须打开两条TCP连接,一条连接客户端,一条连接应用。在服务器收到很多连接时,系统的可用端口将很快被耗尽。通过修改net.ipv4.ip_local_port_range参数,可以将可用端口的范围改大。如果在/var/log/syslog中发现有这样的错误: “possible SYN flooding on port 80. Sending cookies”,即表明系统找不到可用端口。增大net.ipv4.ip_local_port_range参数可以减少这个错误。
net.ipv4.tcp_tw_reuse
当服务器需要在大量TCP连接之间切换时,会产生大量处于TIME_WAIT状态的连接。TIME_WAIT意味着连接本身是关闭的,但资源还没有释放。将net_ipv4_tcp_tw_reuse设置为1是让内核在安全时尽量回收连接,这比重新建立新连接要便宜得多。
net.ipv4.tcp_fin_timeout
这是处于TIME_WAIT状态的连接在回收前必须等待的最小时间。改小它可以加快回收。
如何检查连接状态
使用netstat:
或使用ss:
随着web服务器的负载逐渐升高,我们就会开始遭遇NginX的某些奇怪限制。连接被丢弃,内核不停报SYN flood。而这时,平均负荷和CPU使用率都很小,服务器明明是可以处理更多连接的状态,真令人沮丧。
经过调查,发现有非常多处于TIME_WAIT状态的连接。这是其中一个服务器的输出:
有47135个TIME_WAIT连接!而且,从ss可以看出,它们都是已经关闭的连接。这说明,服务器已经消耗了绝大部分可用端口,同时也暗示我们,服务器是为每个连接都分配了新端口。调优网络对这个问题有一点帮助,但是端口仍然不够用。
经过继续研究,我找到了一个关于上行连接keepalive指令的文档,它写道:
设置通往上游服务器的最大空闲保活连接数,这些连接会被保留在工作进程的缓存中。
有趣。理论上,这个设置是通过在缓存的连接上传递请求来尽可能减少连接的浪费。文档中还提到,我们应该把proxy_http_version设为"1.1",并清除"Connection"头部。经过进一步的研究,我发现这是一种很好的想法,因为HTTP/1.1相比HTTP1.0,大大优化了TCP连接的使用率,而Nginx默认用的是HTTP/1.0。
按文档的建议修改后,我们的上行配置文件变成这样:
我还按它的建议修改了server一节的proxy设置。同时,加了一个 p roxy_next_upstream来跳过故障的服务器,调整了客户端的 keepalive_timeout,并关闭访问日志。配置变成这样:
采用新的配置后,我发现服务器们占用的socket 降低了90%。现在可以用少得多的连接来传输请求了。新的输出如下:
得益于事件驱动式设计可以异步处理I/O,Node.js开箱即可处理大量的连接和请求。虽然有其它一些调优手段,但这篇文章将主要关注node.js的进程方面。
Node是单线程的,不会自动使用多核。也就是说,应用不能自动获得服务器的全部能力。
实现Node进程的集群化
我们可以修改应用,让它fork多个线程,在同一个端口上接收数据,从而实现负载的跨越多核。Node有一个cluster模块,提供了实现这个目标所必需的所有工具,但要将它们加入应用中还需要很多体力活。如果你用的是express,eBay有一个叫cluster2的模块可以用。
防止上下文切换
当运行多个进程时,应该确保每个CPU核同一时间只忙于一个进程。一般来说,如果CPU有N个核,我们应该生成N-1个应用进程。这样可以确保每个进程都能得到合理的时间片,而剩下的一个核留给内核调度程序运行其它任务。我们还要确保服务器上基本不执行除Node.js外的其它任务,防止出现CPU的争用。
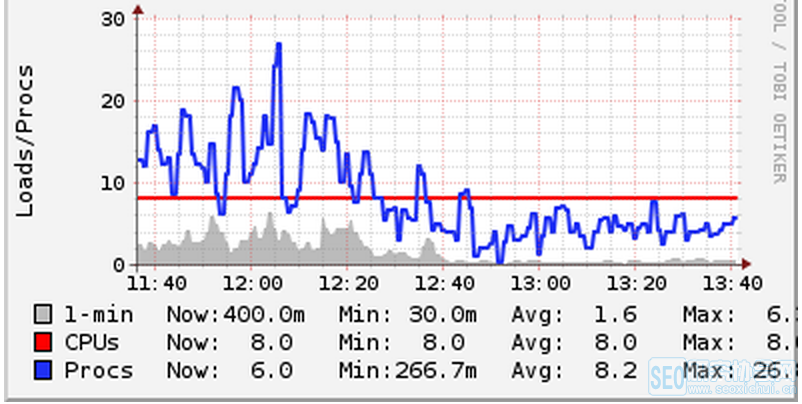
我们曾经犯过一个错误,在服务器上部署了两个node.js应用,然后每个应用都开了N-1个进程。结果,它们互相之间抢夺CPU,导致系统的负荷急升。虽然我们的服务器都是8核的机器,但仍然可以明显地感觉到由上下文切换引起的性能开销。上下文切换是指CPU为了执行其它任务而挂起当前任务的现象。在切换时,内核必须挂起当前进程的所有状态,然后装载和执行另一个进程。为了解决这个问题,我们减少了每个应用开启的进程数,让它们公平地分享CPU,结果系统负荷就降了下来:
请注意上图,看系统负荷(蓝线)是如何降到CPU核数(红线)以下的。在其它服务器上,我们也看到了同样的情况。既然总的工作量保持不变,那么上图中的性能改善只能归功于上下文切换的减少。 |
如何为高负载网络优化Nginx 和 Node.js?
在搭建高吞吐量web应用这个议题上,NginX和Node.js可谓是天生一对。他们都是基于事件驱动模型而设计,可以轻易突破Apache等传统web服务器的C10K瓶颈。预设的配置已经可以获得很高的并发
相关推荐
您可能还对这些文章感兴趣

Vue.js组件开发教程进阶高级特性详解
这篇文章讲了Vue.js组件开发里几个能让你少加班的高级特性,比如动态组件和作用域插槽。作者用电商团队重构代码的真实案例说明,光靠这两个东西就能砍掉40%的冗余逻辑。文章不是讲花架子,而是分享怎么让页面像搭积木一样灵活,帮您减少代码量、提升维护效率。说白了,就是教您把Vue用得更聪明,别再当“模板引擎”使了。

Vue.js教程零基础学习路线图
这篇文章讲的是零基础怎么学Vue.js,作者用很接地气的方式分享了一条学习路线图。他建议别一上来就碰框架,得先花两周搞定HTML这个地基,比如标题、段落、图片这些基础标签。作者还举了个例子,有个做销售的朋友完全零基础,四个月就搭出了公司内部系统,说明只要按步骤来,三个月就能做出自己的项目。总之,别怕,一步步走就行。

Vue.js组件开发教程项目实战案例分析
这篇文章讲的是Vue.js组件开发如何帮您提升项目效率,用一物一码行业的真实案例——帮高端茶叶客户搭建防伪溯源系统——来说明。文章分享了一个惨痛教训:如果每个产品系列都单独写页面,后期改起来会让人崩溃。通过这个例子,作者用大白话教您怎么用组件化思路避免重复劳动,让代码能复用、好维护。

Vue.js组件开发教程零基础学习路线图
这篇文章分享了一条特别适合Vue.js新手的组件开发学习路线。作者就像朋友聊天一样,先帮您理解组件就像“乐高积木”的本质,解决新手从看懂文档到动手实践的常见困惑。文章不讲空理论,而是一步步教您如何写出整洁、可复用的组件,还会穿插聊聊ESLint规范代码和SSL证书的重要性,目标就是让您学完能用到真实项目里。
需要专业的软件开发服务?
郑州微易网络科技有限公司,15+年开发经验,为您提供专业的小程序开发、网站建设、软件定制服务
技术支持:186-8889-0335 | 邮箱:hicpu@me.com